Session unit tests
Unit test of complete user sessions
This type of unit test is used form running more complex test of whole reference user sessions. It allows to replay specific users interactions with restoring the chain/agent memory to the exact state as it was in during the conversation. This allows you to evaluate the effect of changes in your code, prompts, tools and overall setup on the conversation flow.
How to setup your Session level tests
1. ensure that you use tracking_project attribute
In order to distinguish between multiple potential "dev" projects, we need to label the "setup". We do this using tracking_project attribute of PromptWatch context. Alternatively this can be setup as an ENV variable (which is neat, if you set it up per project in VS code launch.json).
2. run some experiments with your registered template
We need track some real and representative examples that will be used for reference.
You can skip this step, you have been using tracking_project attribute,
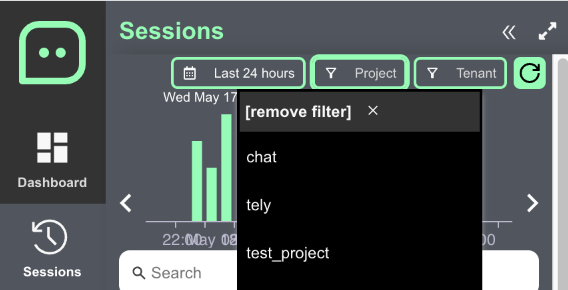
3. annotate the sessions
Find some representative sessions using filter
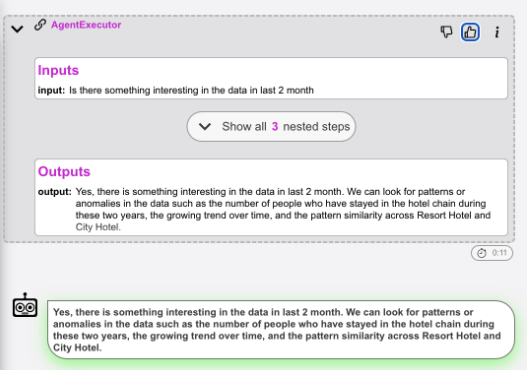
And annotate the good and bad examples by 👍👎. These examples will be used as a reference (similar to defining assert val=="desired value" or assert val!="unwanted value" in traditional programming). The difference is that we wont be using exact value equality here. See unit test evaluation for more detail
4. setup your test and run it
from promptwatch.unit_tests import UnitTest
def build_your_chain():
"""
What ever code you need to build your chain
"""
...
llmChain = build_your_chain()
# now we create a unit test context specifying the name of the test an the source of test cases (for_prompt_template in our case)
with UnitTest("the_name_of_the_test").for_prompt_template("the_name_of_the_template") as test:
# IMPORTANT! - we need to replace the memory if we use one, to reset it after each test
llmChain.memory = test.langchain.get_test_memory()
# iterate over the test cases
for test_case in test.test_cases():
# evaluate the method
test_case.evaluate(llmChain.run)
In this case it is important to use specific memory dedicated for unit testing. It will ensure that on each iteration we will feed only the proper input for that test case.
Since the test is basically a loop, the memory would automatically accumulate history of conversation from previous steps. This might be ok, if we would only have annotated chains from single session, but that is typically not the case.
If you omit this step, you will see the accumulation of the history in the tracing logs.
For more advanced scenarios please see Unit test reference guide